前篇我們介紹了關於機器學習的基礎名詞以及分類總集,接下來就讓我們細講人工神經網路的運作原理及基礎結構吧!
※注意※ 英文專有名詞翻譯過來可能有許多種版本,筆者這邊使用直譯的方式,還請見諒~
Neuron 神經元
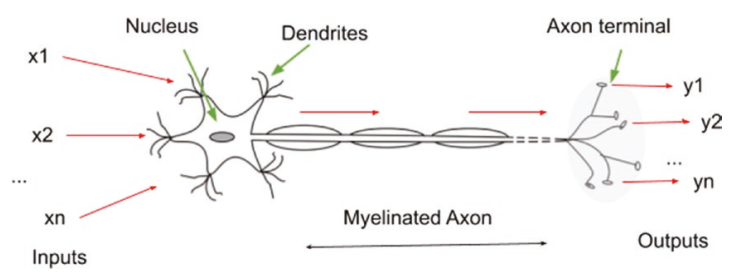
人工神經網路設計成像是人類腦袋運作的計算系統。
單個精神網路的精神元被稱作感知器(Perceptron),對輸入信號進行操作和產生輸出。一個典型的神經網路包含多個精神元,神經元的輸入來自資源(相機或感測裝置)或者是其他精神源的輸出。
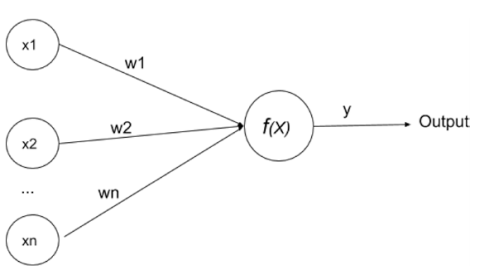
x1, x2, x3, … xn都是輸入信號(如: 圖片特徵點),而w1, w2, w3, … wn是個別輸入信號的權重 ,f(x) 處理單元被稱作neuron,透過actication function 由neuron產生輸出。
Perceptron 感知器
一顆在神經網路的neuron被稱作感知器 (perceptron)
每個感知器實作數學方法去操作輸入信號並產生輸出
單個感知器是最簡單的神經網路
典型的精神網路由多個neuron組成
Neuron的輸入如不是來自於實體物件的來源 就是來自於其他neuron的輸出
感知器的學習目標是決定每個輸入信號的理想權重(weights) 學習演算法任意為節點指派權重。單一數值呈上對應的權重,每個信號的product(權重乘上單一值)會被加入計算輸出上。而優化方法(optimization function)使用5-2來優化權重,計算重複執行,直到給予輸入集合的權重完全優化為止。
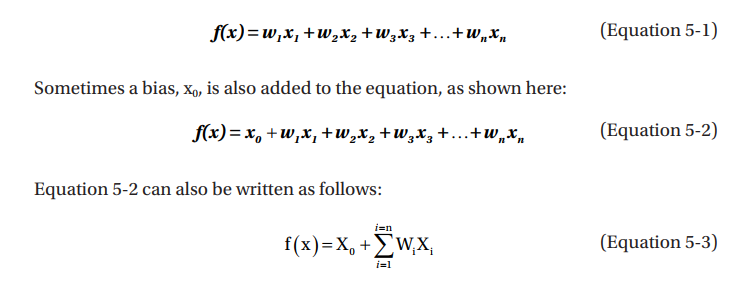
Multi Layer Perceptron多層感知器
一個人工精神網路包含多個neuron,輸入由一組neurons處理。一組裡每個neuron各自處理輸入。來自這組neuron的輸出會傳送給單個neurons或另一組neurons去執行下一次處理。
層面(Layer)需要多少個便可產生多少個,這種多層管理neuron的方式在神經網路中被廣泛認知為多層感知器 MLP。
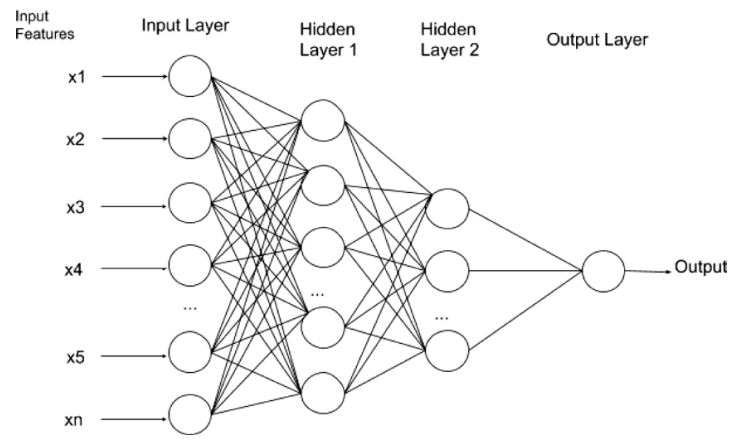
單體neuron塑造了輸入和輸出之間的線性關係,機器學習演算法像是線性回歸和邏輯回歸同樣塑造線性關係。但是絕大多數現實世界的問題並不存在線性關係,多層感知器模組是屬於非線性關係且能夠塑造出更貼近現實世界的問題。
下篇接續~


 iThome鐵人賽
iThome鐵人賽